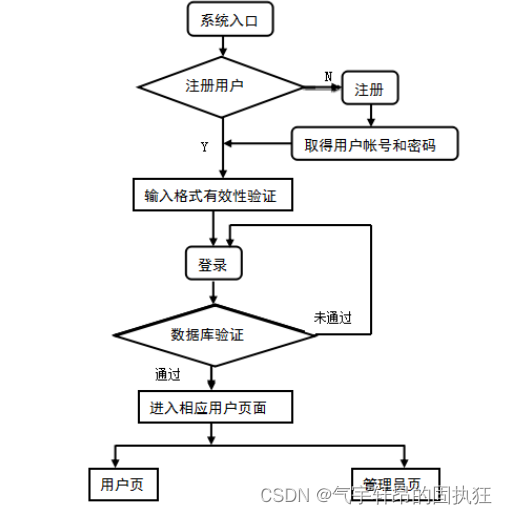
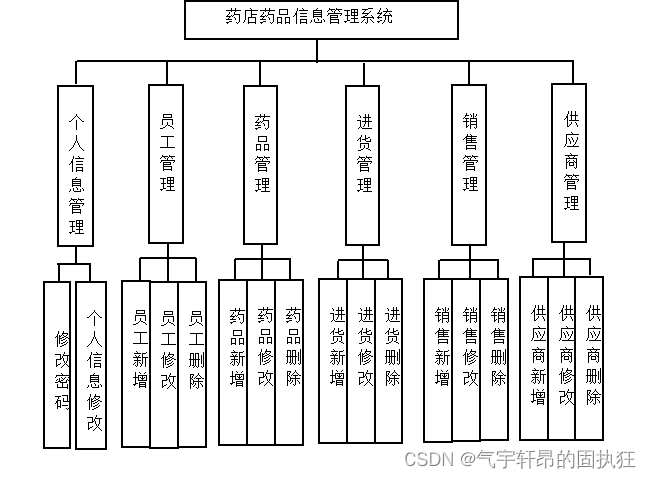
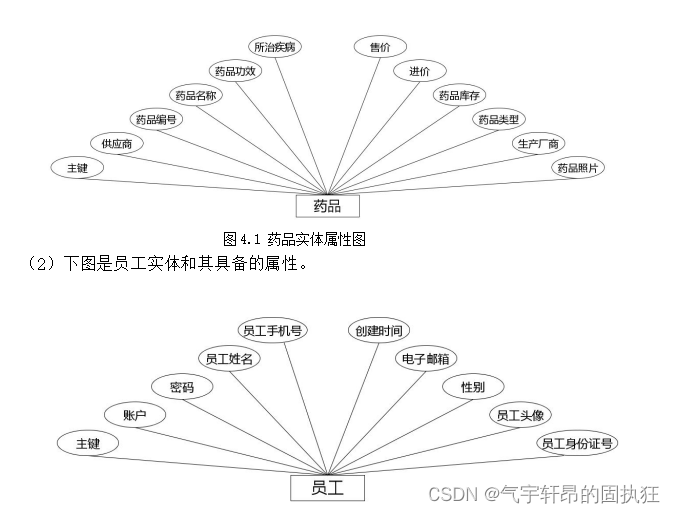
当前位置: 首页 > news >正文 网站 拉新做网站订阅号 news 2025/12/14 15:05:58 网站 拉新,做网站订阅号,商家免费网站模板,关键词首页排名优化公司推荐演示视频: ssmvue的药店药品信息管理系统(有报告)。Javaee项目,ssm vue前后端分离项目。 项目介绍: 采用M(model)V(view)C(controller)三层体系结…演示视频: ssm+vue的药店药品信息管理系统(有报告)。Javaee项目,ssm vue前后端分离项目。 项目介绍: 采用M(model)V(view)C(controller)三层体系结构,通过Spring + SpringMvc+ Mybatis+Vue+Maven来实现。MySQL数据库作为系统数据储存平台,实现了基于B/S结构的Web系统。界面简洁,操作简单。 报告截图: 查看全文 http://www.sadfv.cn/news/121/ 相关文章:
演示视频: ssm+vue的药店药品信息管理系统(有报告)。Javaee项目,ssm vue前后端分离项目。 项目介绍: 采用M(model)V(view)C(controller)三层体系结构,通过Spring + SpringMvc+ Mybatis+Vue+Maven来实现。MySQL数据库作为系统数据储存平台,实现了基于B/S结构的Web系统。界面简洁,操作简单。 报告截图: 查看全文 http://www.sadfv.cn/news/121/ 相关文章: