做佩戴护身符的厂家网站凡科网建站模板
文章目录
- 前言
- 一、隔空取物
- 1、XR Grab Interactable
- 2、调节扔出去时的相关系数
- 3、用手柄射线指向需要抓取的物体后,按下侧边扳机键即可抓取
- 二、接触抓取物体
- 1、替换手柄上抓取物体的脚本
- 2、在手柄上添加 接触抓取物体的脚本
- 3、在手柄上添加碰撞盒触发器
- 4、在需要抓取的物体上,做一些调整
- 三、使用接触抓取物体脚本,制作一个可以拉开的门
- 1、对门体添加 XR Grab Interactor组件,并且对其赋值可以抓取的位置
- 2、给门体添加铰链,防止把门抓了起来
前言
在之前的文章中,我们实现了PICO中的移动。
- Unity中PICO实现移动交互
在这篇文章中,我们在Unity中实现PICO的隔空取物。
一、隔空取物
- 给我们需要抓取的物体添加对应组件
1、XR Grab Interactable
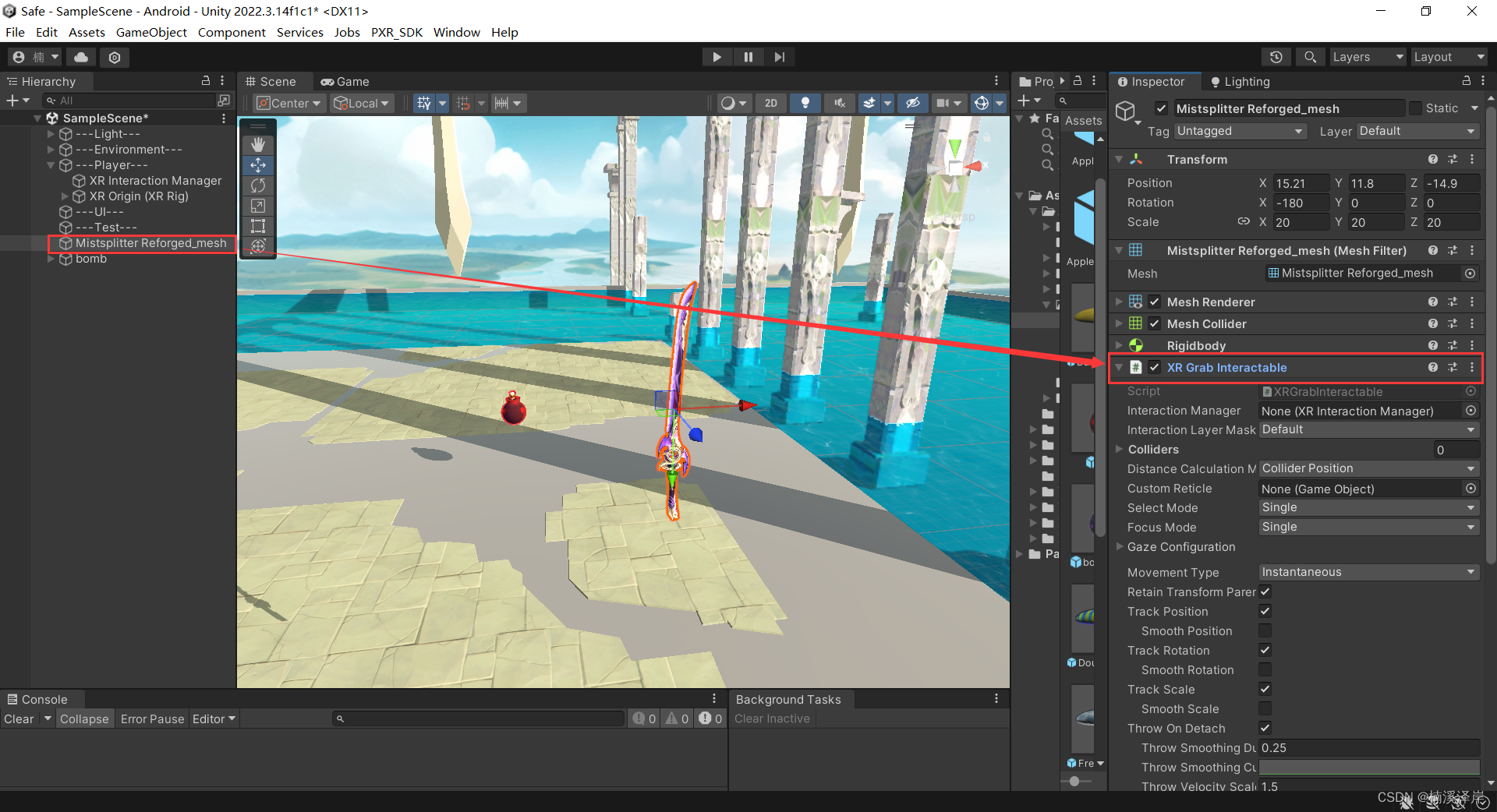
2、调节扔出去时的相关系数
- 可以调节扔出去时的 速度、旋转
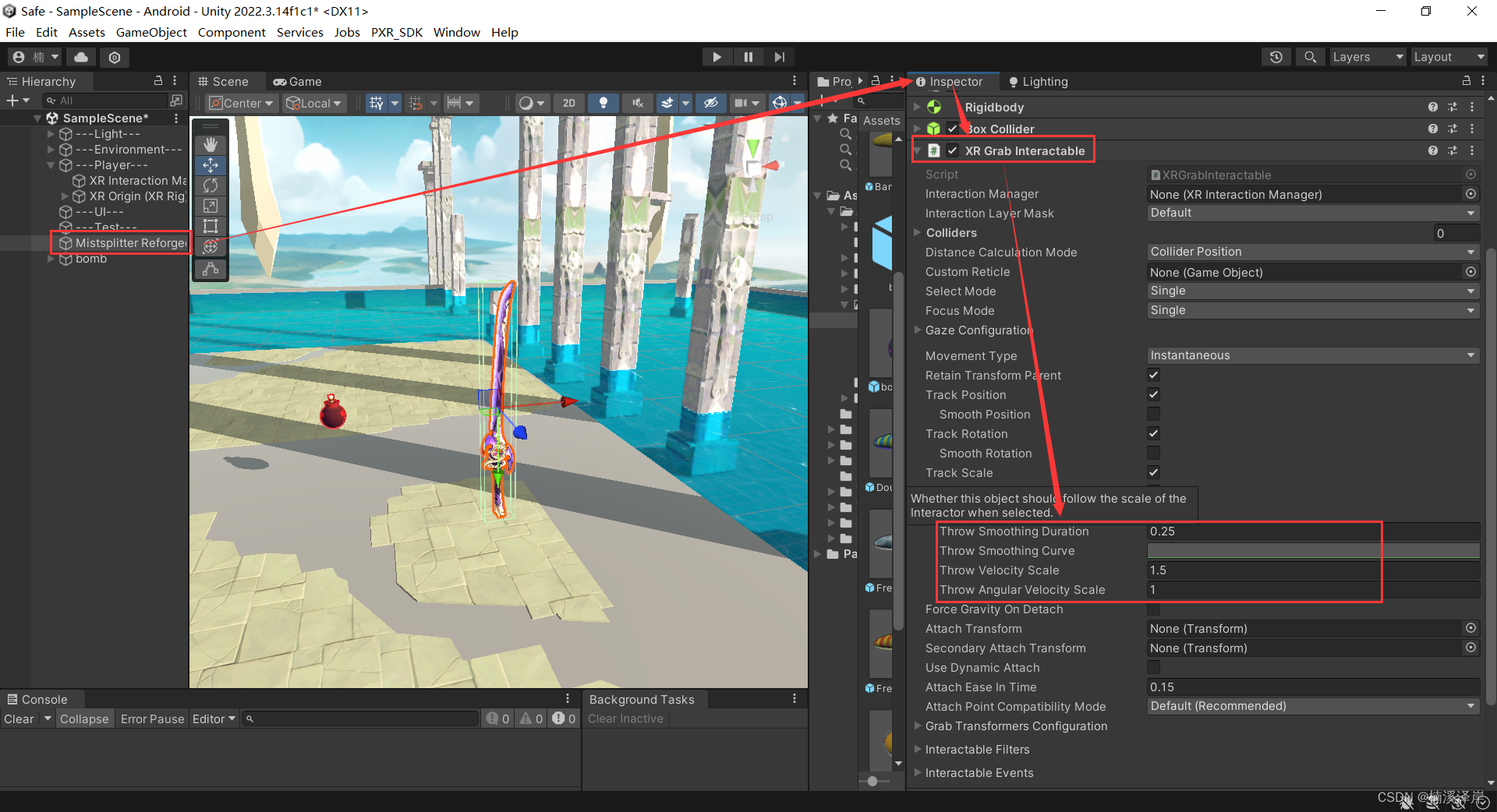
3、用手柄射线指向需要抓取的物体后,按下侧边扳机键即可抓取
二、接触抓取物体
1、替换手柄上抓取物体的脚本
- 删除手柄上的这三个组件
- XR Ray Interactor
- Line Renderer
- XR Interactor Line Visual

2、在手柄上添加 接触抓取物体的脚本
- XR Direct Interactor
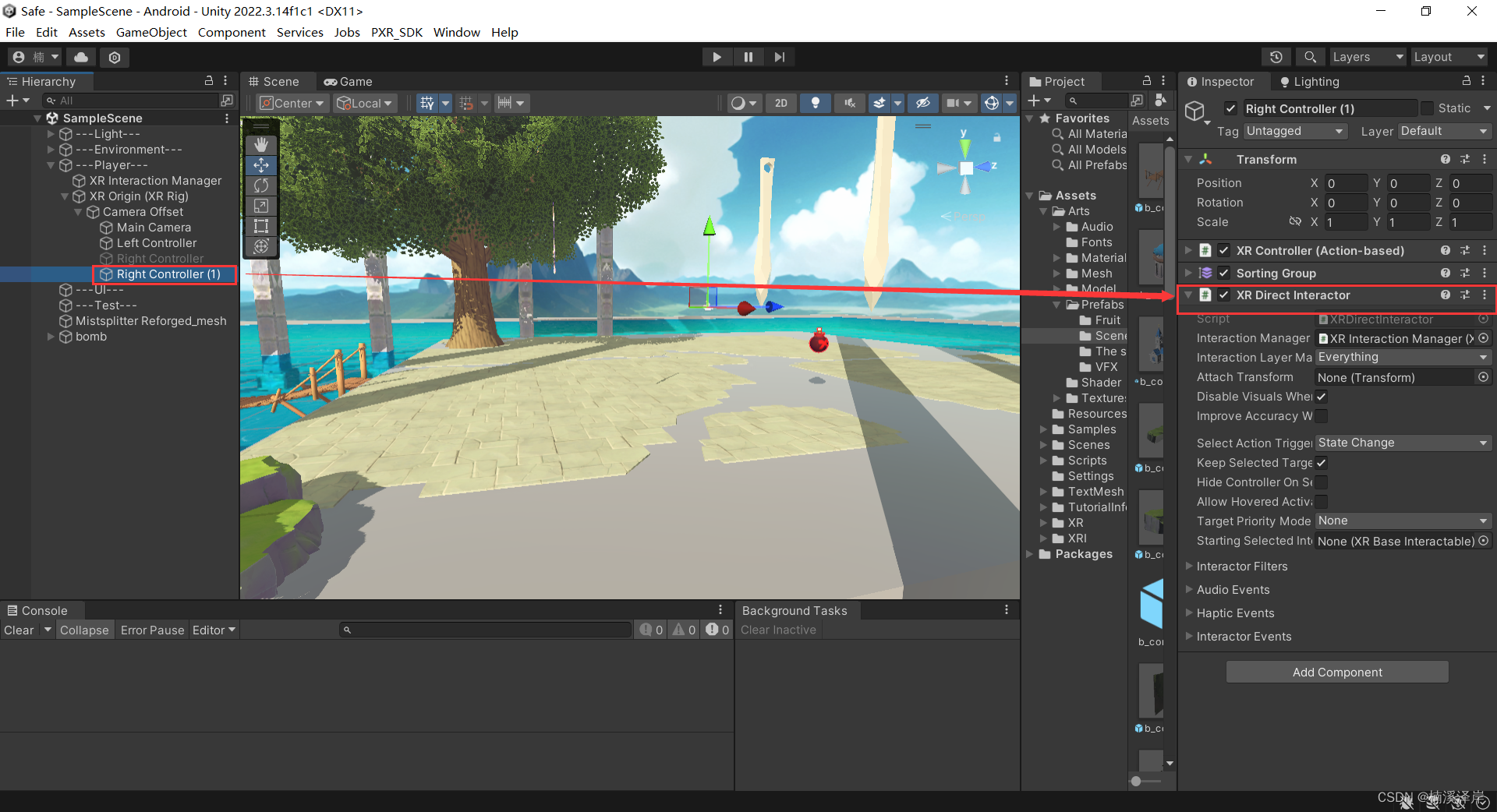
3、在手柄上添加碰撞盒触发器
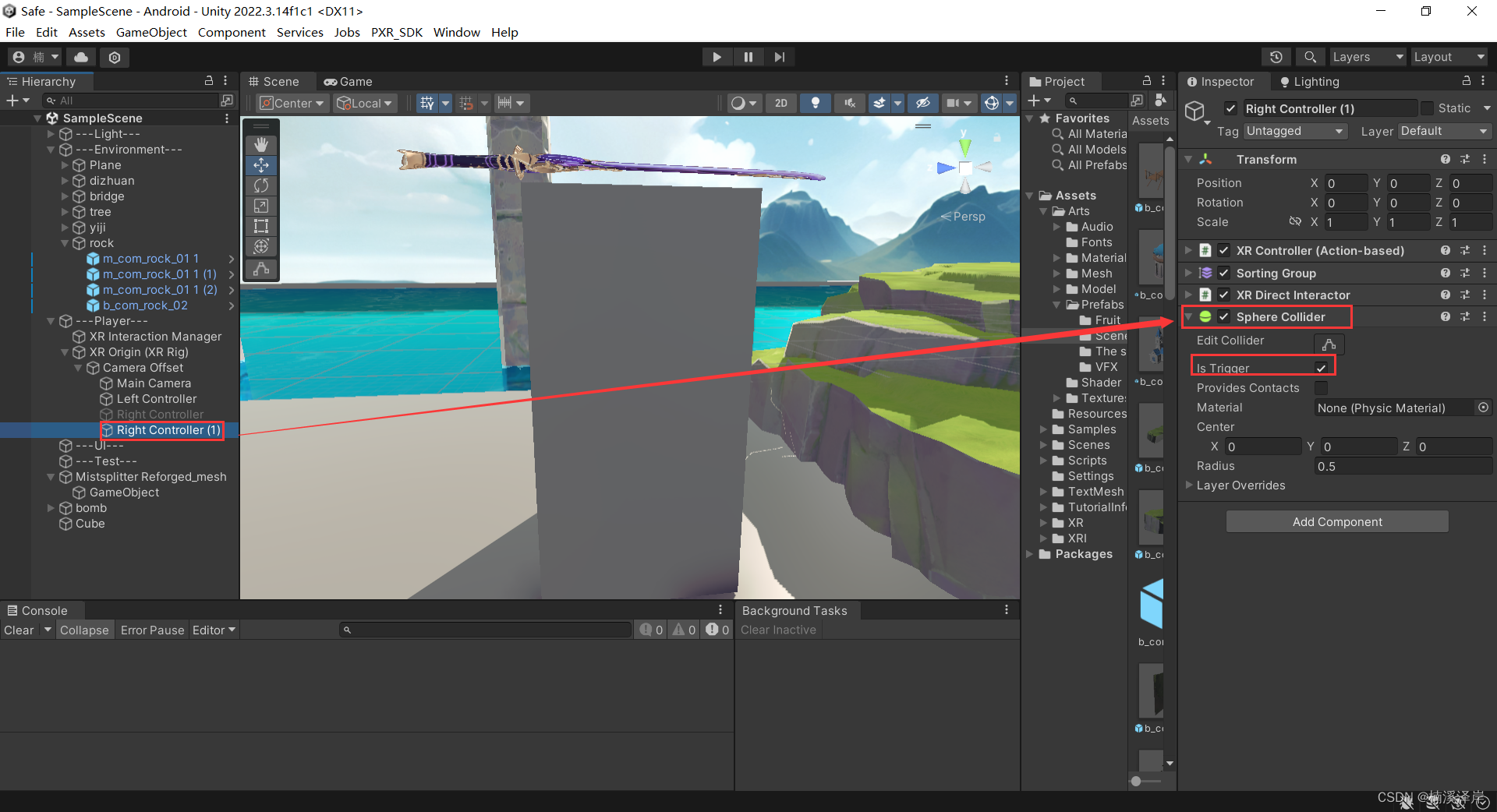
4、在需要抓取的物体上,做一些调整
-
在XR Grab Interactor脚本上勾选抓取静态的物体,防止物体抓取后旋转
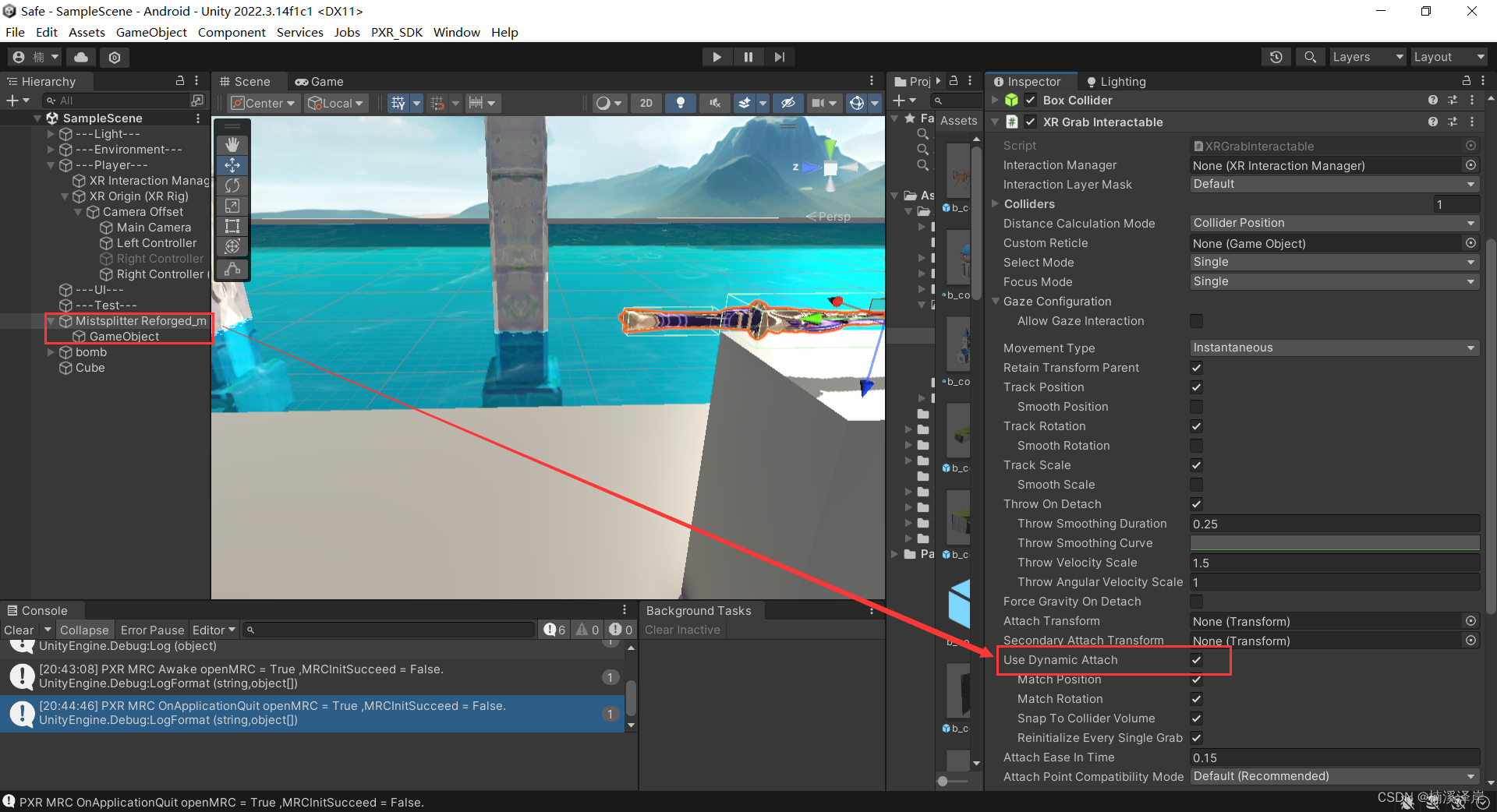
-
给物体允许抓取的位置,添加 空物体 及 添加抓取区域的碰撞盒
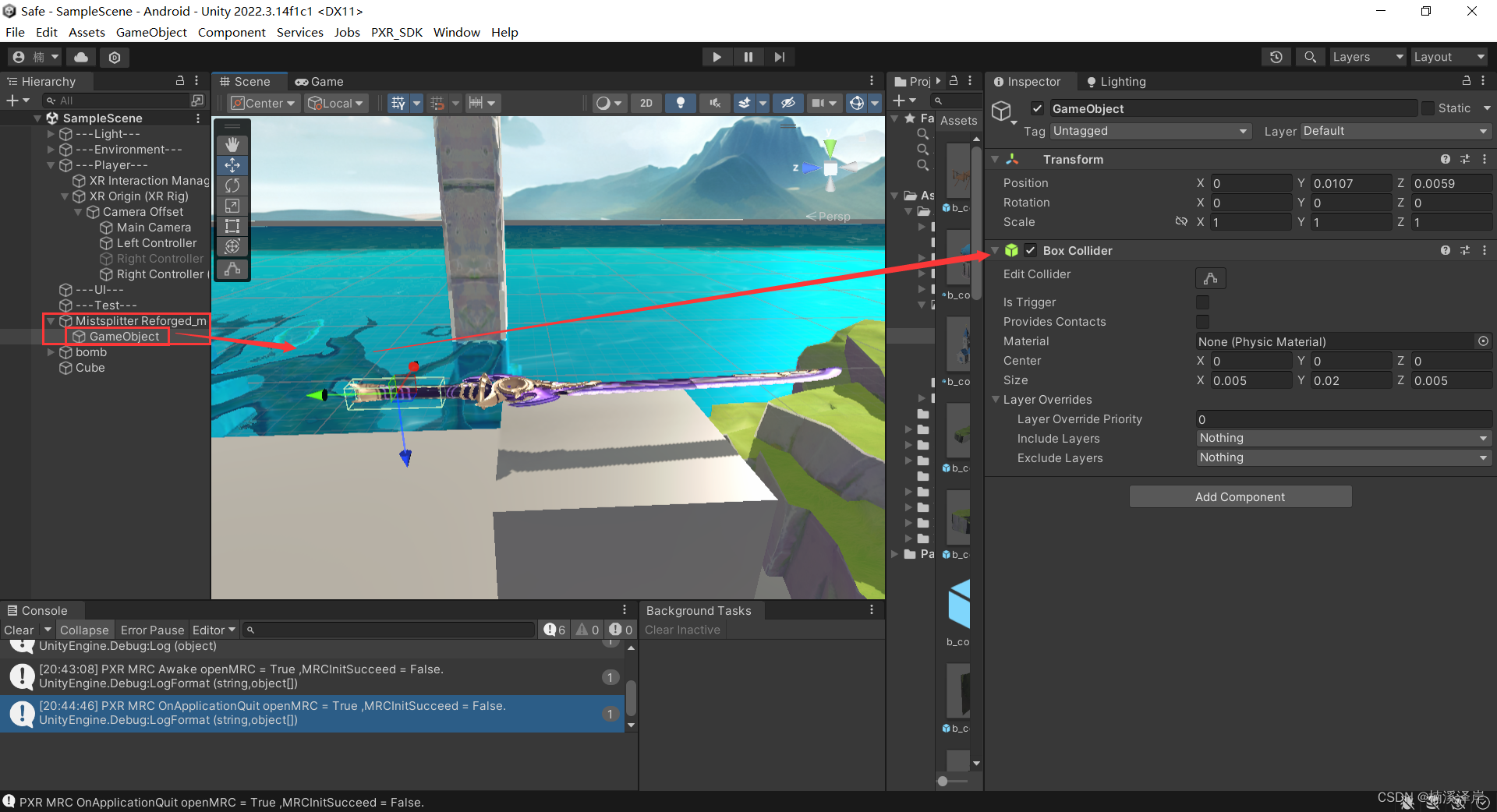
-
把碰撞盒挂载在 接触抓取物体的脚本上
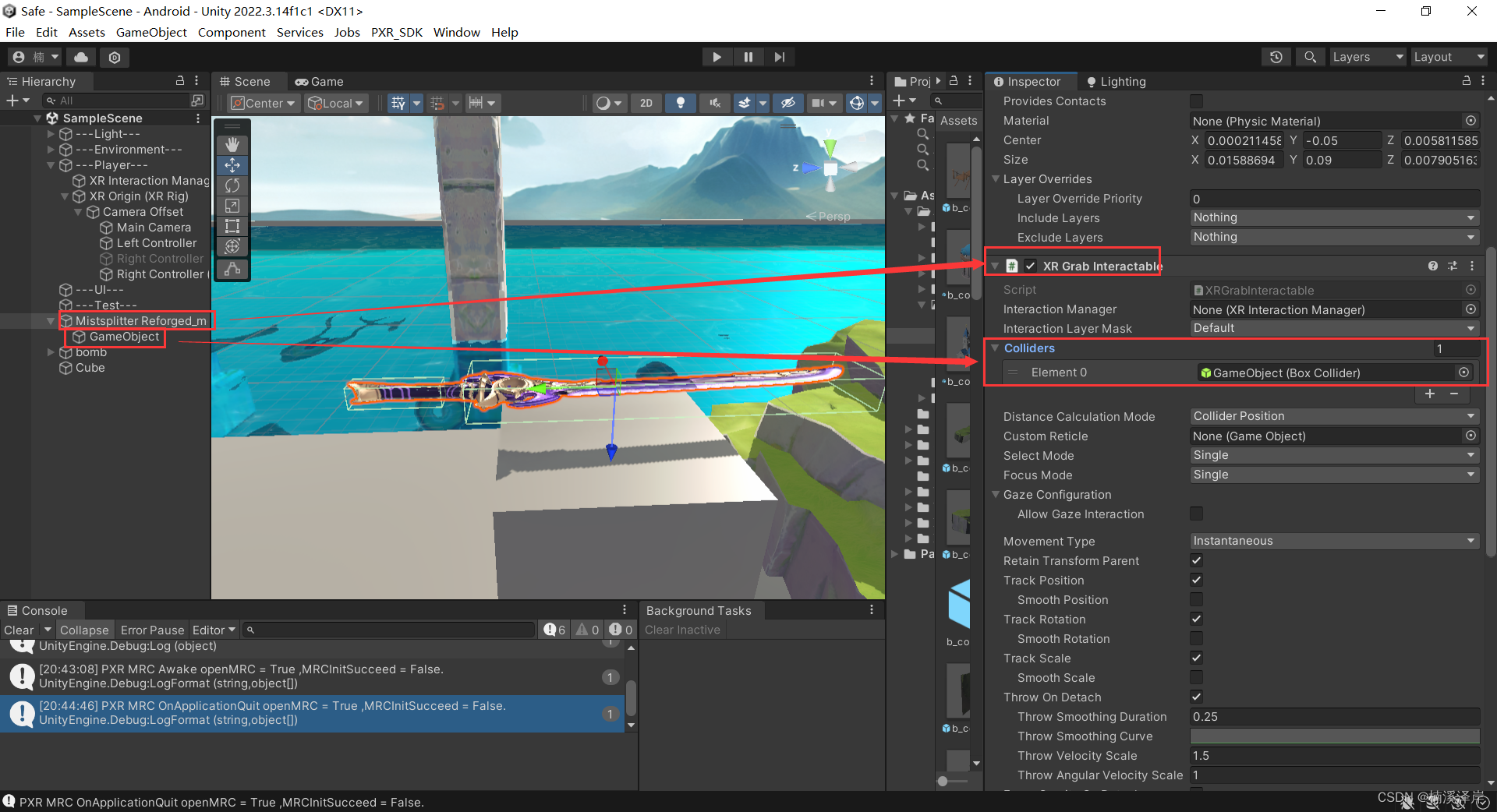
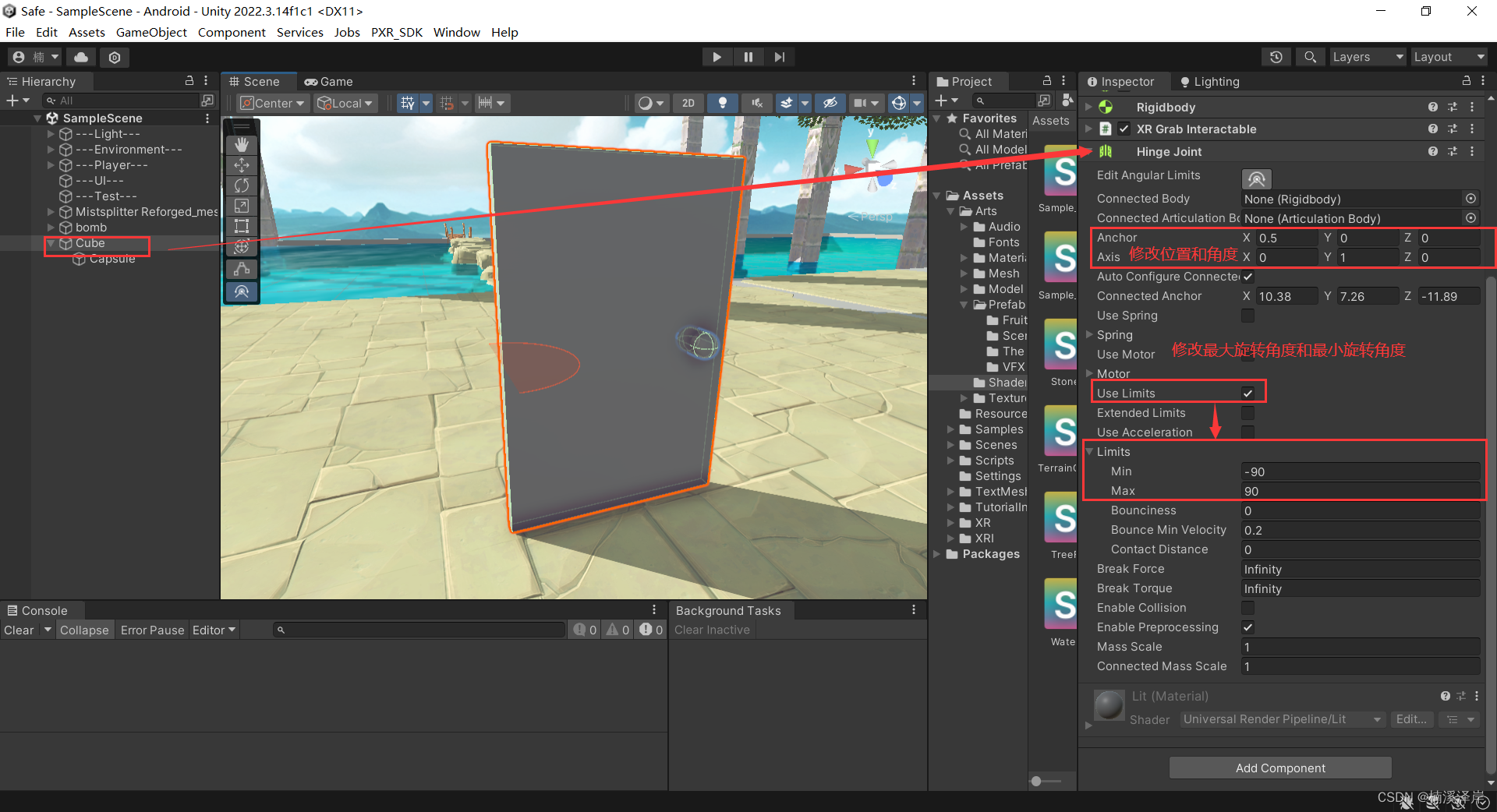
三、使用接触抓取物体脚本,制作一个可以拉开的门
1、对门体添加 XR Grab Interactor组件,并且对其赋值可以抓取的位置
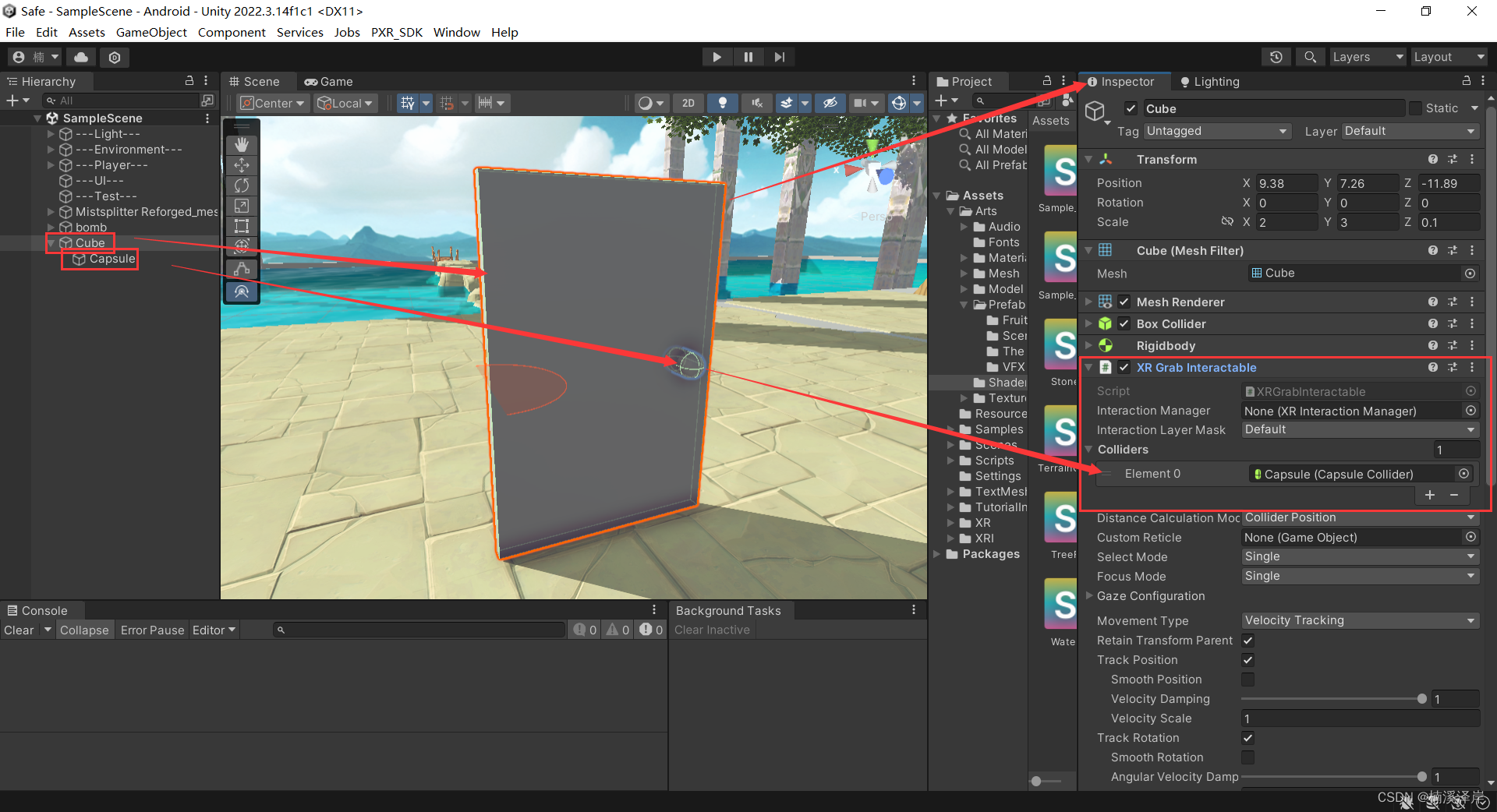
2、给门体添加铰链,防止把门抓了起来
- 修改铰链位置和角度
- 修改铰链允许旋转的范围