茂名公司网站开发免费注册网站哪个好
有不少朋友问到了关于企业网络QoS配置,这个确实在实际网络应用中非常多,基本上大部分企业或个人都用到这个功能,本期我们详细了解下QoS如何对宽带进行限制,QoS如何企业中应用。
一、什么是QoS?
Qos是用来解决网络延迟和阻塞等问题的一种技术。当网络过载或拥塞时,QoS能确保重要业务量不受延迟或丢弃,同时保证网络的高效运行。
直接点说就是能够有效地分配网络带宽,更加合理地利用网络资源。
一般我们用这个功能,就是用来限速的,限制某个设备的上传带宽与下载带宽,路由器与交换机中都可以设置。
例如在网络中,你发现网速较慢,估计是有人占用了带宽,那么你可以在路由器对其设备的ip地址进行限制,限制他的上传及下载带宽。
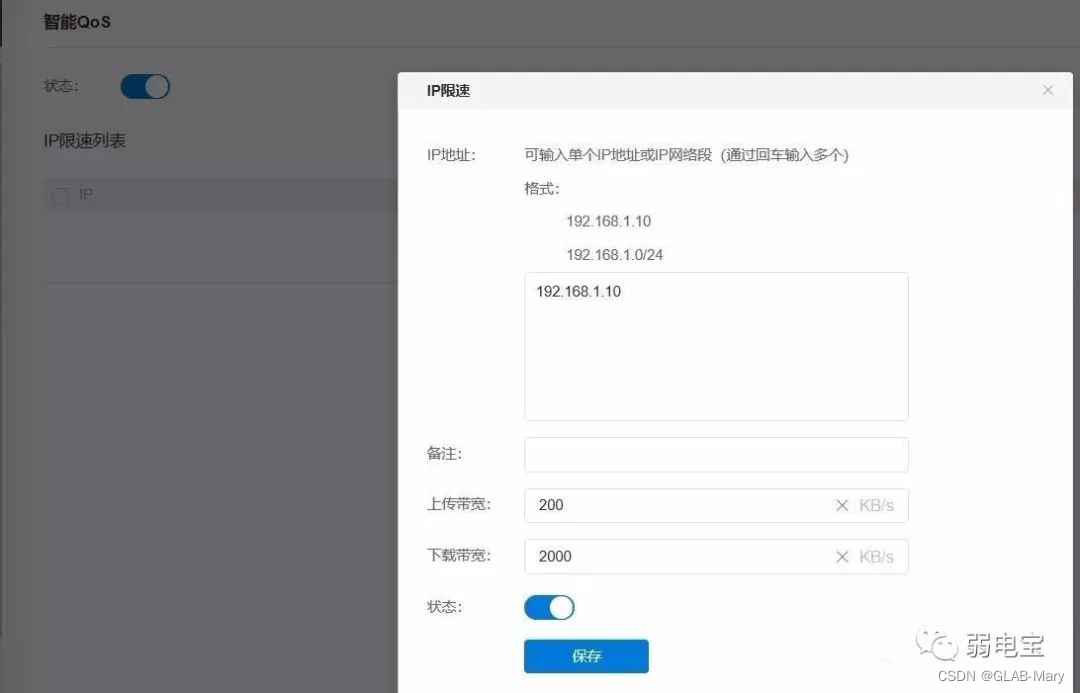
在路由器限制某个设备ip上传及下载带宽。
二、案例:对企业带宽流量进行限制
Qos限数除了小型网络可以在路由器中设置外,同时在大型网络中也可以在交换机中对其配置,如何对企业带宽流量进行限制,我们以华为交换机为例,每一行都有注释。
一、项目情况:
某公司有两个部门,由于该网络只有数据业务流量,不需要对业务进行区分,但是网络带宽有限,因此需要对企业部门1和企业部门2的接入带宽进行整体限制。
要求:
企业部门1带宽限制为8Mbit/s,最高不超过10Mbit/s;
企业部门2带宽限制为5Mbit/s,最高不超过8Mbit/s。
如下图:
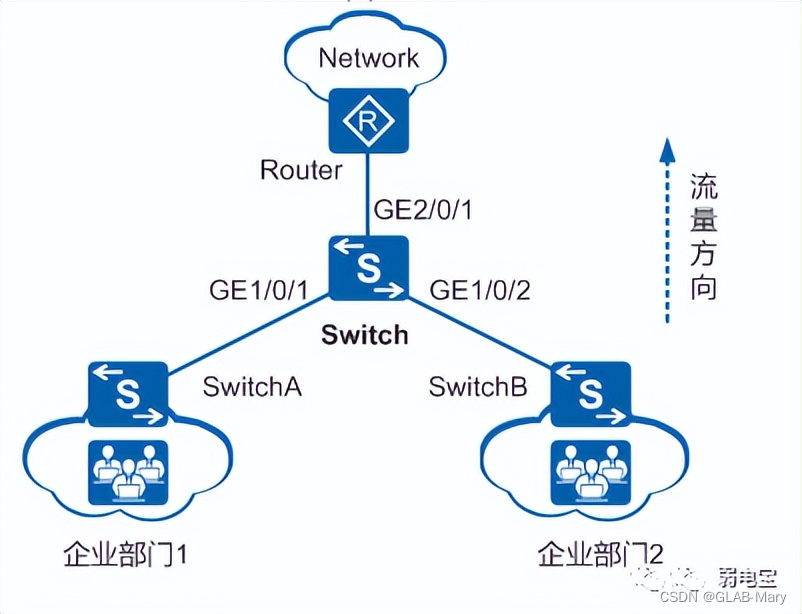
企业部门1和企业部门2通过接口GE1/0/1和GE1/0/2接入Switch,经由Switch和路由器访问网络。
二、配置思路
采用如下的思路配置针对不同网段用户限速:
1、创建VLAN,并配置各接口,使用户能够通过Switch访问网络。
2、创建不同的CAR模板并配置其中的CIR、PIR,在Switch接口GE1/0/1和GE1/0/2的入方向上分别应用CAR模板,实现对不同企业部门的限速功能。
三、操作步骤
1、创建VLAN并配置Switch各接口
#创建VLAN100和VLAN200。

#配置接口GE1/0/1、GE1/0/2和GE2/0/1的接口类型为Trunk,并将GE1/0/1加入VLAN100,GE1/0/2加入VLAN200,GE2/0/1加入VLAN100和VLAN200。

这里弱电行业网补充下:
port link-type access和port link-type trunk的区别?
Access类型端口:只能属于1个VLAN,一般用于连接设备端口;
Trunk类型端口:可以允许多个VLAN通过,可以接收和发送多个VLAN 报文,一般用于交换机与交换机相关的接口。
trunk叫主要用于主干,access可以理解为接入。一般在汇聚交换机和接入交换机之间的端口选择trunk,接入交换机和PC之间的口设置为access。
trunk口可允许通过多条vlan,access口一般只属于1个vlan。
2、配置CAR模板
#在Switch上创建CAR模板car1、car2,分别对企业部门1和企业部门2的流量进行限速。

3、应用CAR模板
#在Switch的接口GE1/0/1、GE1/0/2上的上行方向分别应用car1、car2,对企业部门1和企业部门2的流量进行限速。
