网站添加邮件发送怎么做wordpress更新计划
目录
1 如何设计一个灵活可靠的连接器
2 主要组件介绍
在上一篇,我们介绍了Tomcat提供服务的整体结构,本文我们一起来看一下Tomcat的连接器的设计。
在前面我们提到Tomcat主要完成两个功能:
- 处理 Socket 连接,负责网络字节流与 Request 和 Response 对象的转化。
- 加载和管理 Servlet,以及具体处理 Request 请求。
因此 Tomcat 设计了两个核心组件连接器(Connector)和容器(Container)来分别做 这两件事情。连接器负责对外交流,容器负责内部处理。今天我们来看一下连接器里的问题。
1 如何设计一个灵活可靠的连接器
但是做过实际项目的同学应该知道,如果某些工作需要跨部门或者跨公司合作,是一件很麻烦的事情,需要频繁开会、沟通、联调,而且老有问题, 而Tomcat对外通信需要考虑哪些因素呢?
首先是通信协议,应该支持:
- NIO:非阻塞 I/O,采用 Java NIO 类库实现。
- NIO2:异步 I/O,采用 JDK 7 最新的 NIO2 类库实现。
- APR:采用 Apache 可移植运行库实现,是 C/C++ 编写的本地库。
应该支持的应用层协议有:
- HTTP/1.1:这是大部分 Web 应用采用的访问协议。
- AJP:用于和 Web 服务器集成(如 Apache)。
- HTTP/2:HTTP 2.0 大幅度的提升了 Web 性能。
应该完成的功能有:
- 监听网络端口。
- 接受网络连接请求。
- 读取请求网络字节流。
- 根据具体应用层协议(HTTP/AJP)解析字节流,生成统一的 Tomcat Request 对象。 将 Tomcat Request 对象转成标准的 ServletRequest。
- 调用 Servlet 容器,得到 ServletResponse。
- 将 ServletResponse 转成 Tomcat Response 对象。
- 将 Tomcat Response 转成网络字节流。 将响应字节流写回给浏览器。
Tomcat 为了实现支持多种 I/O 模型和应用层协议,一个容器可能对接多个连接器,就好比一个房间有多个门。但是单独的连接器或者容器都不能对外提供服务,需要把它们组装起来才能工作,组装后这个整体叫作 Service 组件。注意,Service 本身没有做什么重要的事情,只是在连接器和容器外面多包了一层,把它们组装在一起。Tomcat 内可能有多个 Service,这样的设计也是出于灵活性的考虑。通过在 Tomcat 中配置多个 Service,可 以实现通过不同的端口号来访问同一台机器上部署的不同应用。
需求列清楚后,我们要考虑的连接器应该有如何设计。
一般我们设计模块,首先考虑的原则就是"高内聚、低耦合",高内聚是指相关度比较高的功能要尽可能集中,不要分散。 低耦合是指两个相关的模块要尽可能减少依赖的部分和降低依赖的程度,不要让两个模块产生强依赖。
通过分析连接器的详细功能列表,我们发现连接器需要完成 3 个高内聚的功能:
- 网络通信。
- 应用层协议解析。
- Tomcat Request/Response 与 ServletRequest/ServletResponse 的转化。
因此 Tomcat 的设计者设计了 3 个组件来实现这 3 个功能,分别是 EndPoint、Processor 和 Adapter。
网络通信的 I/O 模型是变化的,可能是非阻塞 I/O、异步 I/O 或者 APR。应用层协议也是变化的,可能是 HTTP、HTTPS、AJP。浏览器端发送的请求信息也是变化的。
但是整体的处理逻辑是不变的,EndPoint 负责提供字节流给 Processor,Processor 负责提供 Tomcat Request 对象给 Adapter,Adapter 负责提供 ServletRequest 对象给容器。
如果要支持新的 I/O 方案、新的应用层协议,只需要实现相关的具体子类,上层通用的处理逻辑是不变的。
由于 I/O 模型和应用层协议可以自由组合,比如 NIO + HTTP 或者 NIO2 + AJP。Tomcat的设计者将网络通信和应用层协议解析放在一起考虑,设计了一个叫 ProtocolHandler 的接口来封装这两种变化点。各种协议和通信模型的组合有相应的具体实现类。比如: Http11NioProtocol 和AjpNioProtocol。
除了这些变化点,系统也存在一些相对稳定的部分,因此 Tomcat 设计了一系列抽象基类来封装这些稳定的部分,抽象基类 AbstractProtocol 实现了 ProtocolHandler 接口。每 一种应用层协议有自己的抽象基类,比如 AbstractAjpProtocol 和 AbstractHttp11Protocol,具体协议的实现类扩展了协议层抽象基类。下面我整理一下它们的继承关系。
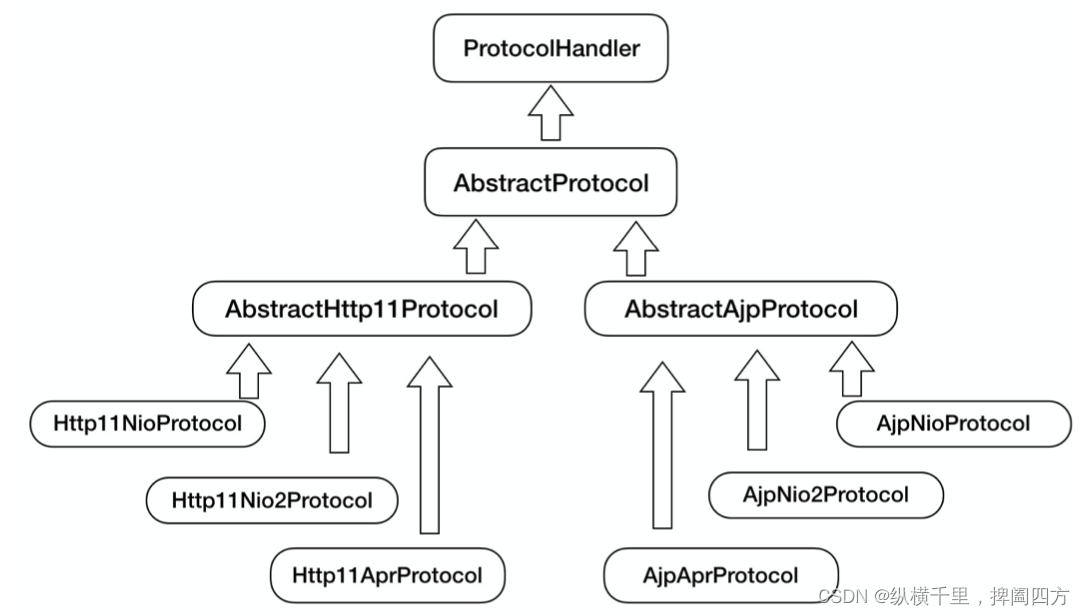
通过上面的图,你可以清晰地看到它们的继承和层次关系,这样设计的目的是尽量将稳定的 部分放到抽象基类,同时每一种 I/O 模型和协议的组合都有相应的具体实现类,我们在使 用时可以自由选择。
总结上面的,连接器模块用三个核心组件:Endpoint、Processor 和 Adapter 来分别做三件事情,其中 Endpoint 和 Processor 放在一起抽象成了 ProtocolHandler 组件,它们的关系如下图所示。

2 主要组件介绍
下面我来详细介绍这两个顶层组件 ProtocolHandler 和 Adapter。
ProtocolHandler 组件
由上文我们知道,连接器用 ProtocolHandler 来处理网络连接和应用层协议,包含了 2 个重要部件:EndPoint 和 Processor,下面我来详细介绍它们的工作原理。
EndPoint
EndPoint 是通信端点,即通信监听的接口,是具体的 Socket 接收和发送处理器,是对传输层的抽象,因此 EndPoint 是用来实现 TCP/IP 协议的。
EndPoint 是一个接口,对应的抽象实现类是 AbstractEndpoint,而 AbstractEndpoint 的具体子类,比如在 NioEndpoint 和 Nio2Endpoint 中,有两个重要的子组件: Acceptor 和 SocketProcessor。
其中 Acceptor 用于监听 Socket 连接请求。SocketProcessor 用于处理接收到的 Socket 请求,它实现 Runnable 接口,在 Run 方法里调用协议处理组件 Processor 进行处理。为 了提高处理能力,SocketProcessor 被提交到线程池来执行。而这个线程池叫作执行器 (Executor),这个会在后面单独研究Tomcat 如何扩展原生的 Java 线程池。
Processor
如果说 EndPoint 是用来实现 TCP/IP 协议的,那么 Processor 用来实现 HTTP 协议, Processor 接收来自 EndPoint 的 Socket,读取字节流解析成 Tomcat Request 和
Response 对象,并通过 Adapter 将其提交到容器处理,Processor 是对应用层协议的抽 象。
Processor 是一个接口,定义了请求的处理等方法。它的抽象实现类 AbstractProcessor 对一些协议共有的属性进行封装,没有对方法进行实现。具体的实现有 AJPProcessor、 HTTP11Processor 等,这些具体实现类实现了特定协议的解析方法和请求处理方式。
我们再来看看连接器的组件图:
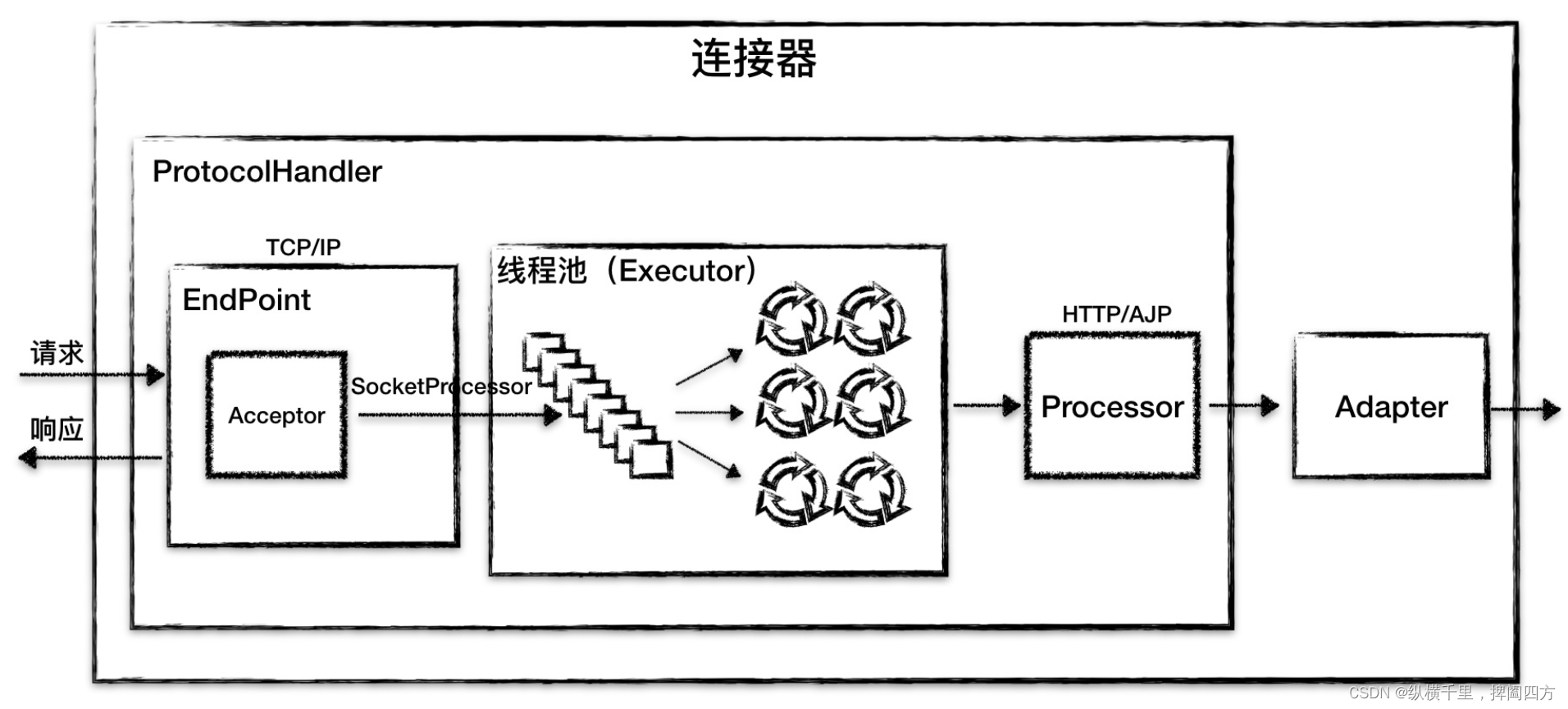
从图中我们看到,EndPoint 接收到 Socket 连接后,生成一个 SocketProcessor 任务提交 到线程池去处理,SocketProcessor 的 Run 方法会调用 Processor 组件去解析应用层协 议,Processor 通过解析生成 Request 对象后,会调用 Adapter 的 Service 方法。
到这里我们学习了 ProtocolHandler 的总体架构和工作原理,关于 EndPoint 的详细设 计,后面我还会专门介绍 EndPoint 是如何最大限度地利用 Java NIO 的非阻塞以及 NIO2 的异步特性,来实现高并发。
Adapter 组件
由于协议不同,客户端发过来的请求信息也不尽相同,Tomcat 定义了自己 的 Request 类来“存放”这些请求信息。ProtocolHandler 接口负责解析请求并生成 Tomcat Request 类。但是这个 Request 对象不是标准的 ServletRequest,也就意味着, 不能用 Tomcat Request 作为参数来调用容器。Tomcat 设计者的解决方案是引入 CoyoteAdapter,这是适配器模式的经典运用,连接器调用 CoyoteAdapter 的 Sevice 方法,传入的是 Tomcat Request 对象,CoyoteAdapter 负责将 Tomcat Request 转成 ServletRequest,再调用容器的 Service 方法。
参考:
本文参考了众多内容,特别是李号双老师的文章