视频网站开发 视频采集黑龙江省农业网站建设情况
价格是你所付出的东西,而价值是你得到的东西

EVO大赛是什么?
“EVO”大赛全称“Evolution Championship Series”,是北美最高规格格斗游戏比赛,大赛正式更名后已经连续举办12年,是全世界最大规模的格斗游戏赛事。常见的比赛项目包括:《街头霸王5》,《铁拳7》,《罪恶装备:启示者》《苍翼默示录:神观之梦》。《拳皇14》,《真人快打》,《漫画英雄VS Capcom3》等。
中文名:Evolution锦标赛
分 类:电子竞技赛事
外文名:Evolution Championship Series
创始时间:1996
前 身:Battle by the Bay
创始人:Tom Cannon等
赛事发展
Evolution Championship Series是一年一度的格斗游戏专业级赛事。在格斗游戏圈中,常常被人简称为“EVO”或“Evo”,是当今首屈一指的格斗游戏赛事。赛事使用双败淘汰制的模式。与日本前顶级规格格斗游戏赛事“斗剧”相比,EVO的赛事也以其全球性著称,当然其中不乏格斗游戏尤其发达的日本方面的顶尖玩家。
Evo由Tom Cannon创立,与此同时Tom Cannon也是格斗游戏专业情报网站Shoryuken(升龙拳)的创始人。赛事的前身是早在1996年于加利福尼亚举办的“Battle by the Bay”赛事,当时聚集了40位玩家一同参与《超级街霸2 Turbo》和《街霸Alpha2》(日版称《街霸Zero2》)的比赛,最终演变为了在拉斯维加斯举办的巡回赛。比赛在2002年正式更名为EVO。比赛规模不断扩大,至2009年,参赛人数已过千。而近年的EVO2014单《终极街霸4》项目的报名人数就已超过2000人。
最早,比赛同斗剧一样采用街机框体,但在2004年,赛方决定从今以后所有项目都使用家用机版本,此举也在当时引起了不小的争议。过后几年,大部分游戏都是用PS3平台,而最近的EVO2014的大部分项目将使用Xbox360平台。除了官方举办的赛事,参与EVO的玩家也历来有着“BYOC”的比赛习惯,即自带家用机举办官方并未涉及的项目比赛。
历届比赛成绩
超级街霸2 Turbo
1.Jason Cole(Dhalsim)
2.大贯晋也(Chunli、Sagat)
3.Jason Deheras(Dhalsim)
4.Apoc(铁面)
漫画英雄 VS 卡普空 2
1.Justin Wong(Storm, Sentinel, Cyclops)
2.Rowtron(Sentinel, Storm, Captain Commando)
3.Combofiend(Magneto, Iron Man, Sentinel)
4.SiN(Sentinel, Cable, Captain Commando)
卡普空 VS SNK 2
1.Tokido(N-E. Honda, Blanka, Sagat)
2.大贯晋也
3.Ken(A-Yun, Iori, Cammy)
4.井上(K-Cammy, Sagat, Blanka)
EVO2003
街霸3 三度冲击
1.K.O(Yun)
2.梅原大吾(Ken)
3.KSK(Alex)
4.井上(Yun、Makoto)
超级街霸2 Turbo
1.梅原大吾(Ryu)
2.大贯晋也(Chunli)
3.John Choi(Sagat)
4.Mike Watson(拳王)
漫画英雄 VS 卡普空 2
1.Justin Wong(Magneto/Cable/Sentinel)
2.Ricky Ortiz(Magneto/Storm/Psylocke, Storm/Sentinel/Captain Commando)
3.Rowtron(Sentinel/Magneto/Cable)
4.kuaneazy(Magneto/Cable/Sentinel)
卡普空 VS SNK 2
1.井上(K- Blanka/Cammy/Sagat)
2.梅原大吾(C-Guile/Cammy/Sagat)
3.Mago(C-Honda/Chun/Blanka)
4.BAS(A-Blanka/Sakura/Bison)
铁拳4
1.Jinkid(Jin Kazama)
2.Jackie Tran(Jin Kazama)
3.TreyPhoenix(Jin Kazama)
4.ChetChetty(Paul Phoenix)
铁拳TT
1.KBM(Jin Kazama/Devil)
2.Ryan Hart(Jin Kazama/Heihachi Mishima)
3.TARE(Lei Wulong/King)
4.JOP( Ogre/True Ogre )
刀魂2
1.DTN(Nightmare)
2.Semi(Astaroth)
4.Floe(Taki)
4.Aris(Voldo)
VR战士4:进化
1.Chibita(Lion Rafale)
2.Ohsu-Akira(Akira Yuki)
3.Ryan Hart(Kage-Maru)
4.Neo Tower(Jacky Bryant)
罪恶装备XX
1.梅原大吾(Sol Badguy)
2.Miu(Sol Badguy)
3.ID(Sol Badguy)
4.Mago(Johnny)
EVO2004
街霸3 三度冲击
1.K.O(Yun)
2.梅原大吾(Ken)
3.Justin Wong(Chunli)
4.Raoh(Chunli)
超级街霸2 Turbo
1.梅原大吾(Ryu、拳王、Sagat)
2.John Choi(Ryu、Sagat、Guile)
3.Kuni(Zangief)
4.Justin Wong(Chunli)
漫画英雄 VS 卡普空 2
1.Justin Wong(Storm/Sentinel/Commando)
2.David Lee(Magneto/Cable/Sentinel)
3.Xecutioner(Sentinel/Storm/Commando)
4.Chris Schmidt(Magneto/Storm/Sentinel)
卡普空 VS SNK 2
1.金豆腐(A-Sakura/Bison/Blanka)
2.Ricky Ortiz(A-Vega/Sakura/Blanka)
3.John Choi(C-Ken/Sagat/Guile)
4.Dan(C-Ken/Ryu/Sagat)
刀魂2
1.RTD(Xianghua, Ivy, Voldo, Nightmare)
2.Mick(Cassandra, Sophitia, Voldo)
3.SowNemesis(Sophitia, Cervantes)
4.Vicious Suicide(Yoshimitsu)
罪恶装备XX
1.梅原大吾(Sol)
2.金豆腐(Eddie)
3.RF(Faust)
4.Shin Kensou(Chipp,Eddie)
VR战士4:进化
1.Itabashi(Shun Di)
2.Shoutime(Sarah)
3.Kurita(Vanessa)
4.Ryan Hart(Kage,Akira)
铁拳4
1.Jackie Tran(Jin)
2.JinKid(Jin)
3.TomHilfiger(Nina,Steve)
4.Aenica(Julia)
铁拳TT
1.Ryan Hart(Jin, Kazuya)
2.Unconkable(Armor King, Devil, Anna)
3.Slips( Julia / Eddy )
4.Shin(Julia / Michelle)
EVO2005
街霸3 三度冲击
1.大贯晋也(Chunli)
2.Justin Wong(Chunli)
3.Nitto(Yun)
4.Mester(Yun)
超级街霸2 Turbo
1.Jaian(Dhalsim)
2.大贯晋也(Chunli)
3.Tokido(Chunli)
4.Phil Burnell(铁面)
铁拳TT
1.Qudans(Jin, Kazuya)
2.Ryan Hart
3.TomHilfiger
4.Slips
卡普空 VS SNK 2
1.D44 BAS(A-Honda/Bison/Blanka)
2.Mago(C-Honda/Sagat/Blanka)
3.金豆腐
4.ComboFiend(A-Rock/Rolento/Eagle)
罪恶装备XX#Reload
1.RF(Faust)
2.金豆腐(Eddie)
3.Miu(Sol)
4.Marn(Eddie)
漫画英雄 VS 卡普空 2
1.Ducvader(Spiral, Cable, Sentinel)
2.Yipes(Magneto, Storm, Psylocke)
3.Potter(Storm, Sentinel, Cable)
4.Justin Wong(Magneto, Storm, Psylocke)
铁拳5
1.Crow(Steve)
2.Yuu(Feng Wei)
3.MadDogJin(Steve)
4.jra64(Nina)
EVO2006
街霸3 三度冲击
1.Nitto(Yun)
2.Issei(Yun)
3.大贯晋也(Chunli)
4.Mester(Yun)
终极街霸2
1.Alex Wolfe(CE 将军、X Dhalsim)
2.Jason Nelson(CE将军、X 将军)
3.Tokido(CE将军)
4.Alex Valle(CE Ryu、X Ryu、CE 将军)
死或生4
1.Perfect Legend(Gen Fu)
2.Master(Hayabusa)
3.thehighguy(Lei Fang)
4.King(Hayabusa)
卡普空 VS SNK 2
1.金豆腐(A-Sakura/Bison/Blanka)
2.Ricky Ortiz(A-Vega/Sakura/Blanka)
3.ComboFiend(K-Ken/Sagat/Cammy)
4.Buktooth(N-Hibiki/Morrigan/Iori)
罪恶装备Slash 组队赛
1.Bas队
2.梅原队
3.Alex G队
4.Mike B队
漫画英雄 VS 卡普空 2
1.Justin Wong(Storm/Sentinel/Cyclops)
2.Chunksta( Sentinel/Storm/Captain Commando, Magneto/Storm/Sentinel)
3.Reset(Magneto/Storm/Psylocke, Magneto/Storm/Sentinel)
4.SooMighty(Magneto/Storm/Psylocke)
铁拳5
1.Crow(Steve)
2.Bronson(Ganryu)
3.Jra64(Steve,Roger Jr.)
4.Justin Wong(Steve,Jack-5)
EVO2007
街霸3 三度冲击
1.大贯晋也(Chunli)
2.Tokido(Chunli)
3.Alex Valle(Ryu、Ken)
4.Mike Wakefield(Makoto)
超级街霸2 Turbo
1.Tokido(铁面)
2.John Choi(Ryu、Sagat)
3.Graham Wolfe(拳王、铁面)
4.Quoc Hung Nguyen(Dee Jay、拳王)
卡普空 VS SNK 2
1.BAS(A-Blanka, Vega, M. Bison)
2.Ricky Ortiz(A-Vega, Sakura, Blanka)
3.Justin Wong(C-Vega, Chun-Li, Sagat/A-Vega, Sakura, Blanka)
4.金豆腐(A-Sakura, M. Bison, Blanka)
VR战士5
1.Itazan(Shun Di)
2.大贯晋也(Aoi,Pai)
3.Jacky(Otome)
4.Tokido(Pai)
漫画英雄 VS 卡普空 2
1.IFC Yipes(Magneto/Storm/Psylocke)
2.Justin Wong(Storm/Sentinel/Cyclops, Magneto/Storm/Psylocke)
3.Smoothviper(Sentinel/Storm/Captain Commando)
4.TehBoogieman(Storm/Sentinel/Captain Commando)
铁拳5:暗黑复苏
1.Arario(Jack-5)
2.Spero Gin(Eddy)
3.InsaneLee(Ganryu)
4.KaNe(Devil Jin)
罪恶装备XX Core 组队赛
1.Yossan队
2.Shittalk队
3.Kabuki队
4.Matlockdown队
Super Smash Bros.Melee
1.SephirothKen(Marth)
2.Hugs(Samus)
3.Mango(Jigglypuff)
4.PC Chris(Falco, Fox)
EVO2008
街霸3 三度冲击
1.大贯晋也(Chunli)
2.Justin Wong(Chunli)
3.Amir Amirsaleh(Chunli)
4.Tokido(Chunli)
超级街霸2 Turbo
1.John Choi(Sagat、Ken)
2.大贯晋也(Chunli)
3.Alex Valle(Ryu、Ken)
4.Tokido(铁面)
漫画英雄 VS 卡普空 2
1.Justin Wong(Sentinel, Storm, Captain Commando)
2.Chunksta(Magneto, Storm, Sentinel)
3.Smoothviper(Magneto, Cable, Sentinel)
4.Crizzle(Magneto, Storm, Psylocke)
卡普空 VS SNK 2
1.John Choi(C-Ken/Cammy/Sagat)
2.BAS(A-Vega/Blanka/Bison)
3.Ricky Ortiz(A-Vega/Sagat/Blanka)
4.Justin Wong(C-Vega/Iori/Sagat, C-Vega/Cammy/Sagat)
铁拳5:暗黑复苏
1.Ryan Hart(Kazuya)
2.Gandido(Devil Jin)
3.Cano(Eddy Gordo)
4.Owen(King)
Super Smash Bros.Brawl
1.CPU(R.O.B.)
2.SephirothKen(Marth)
3.Hall(Snake)
4.SK92(Falco)
EVO2009
街霸4
1.梅原大吾(Ryu)
2.EMP|Justin Wong(Rufus、拳王、Abel)
3.Ed Ma(豪鬼、Zangief)
4.EMP|Sanford Kelly(豪鬼、Cammy)
街霸3 三度冲击
1.Justin Wong(Chunli)、Issei(Yun)
2.Jimmy Tran(Urien)、Rommel(Yang)
3.Ryan Harvey(Chunli)、Mark Rogoyski(Ryu)
4.Alex Valle(Ken)、J.R.Rodriguez(豪鬼)
超级街霸2 高清重制版
1.Quoc Hung Nguyen(拳王、Dee Jay)
2.John Choi(Ryu)
3.Damien Dailidenas(Ken、Zangief)
4.Graham Wolfe(拳王)
漫画英雄 VS 卡普空 2
1.Sanford Kelly(Storm, Sentinel, Captain Commando)
2.Justin Wong(Storm, Sentinel, Cyclops)
3.IFC Yipes(Magneto, Storm, Psylocke)
4.Deus
罪恶装备XX Core Plus
1.Latif(Eddie)
2.Marn(Eddie,Jam)
3.FlashMetroid(May)
4.Hellmonkey(Baiken)
刀魂4
1.Malek(Ivy)
2.KDZaster(Cassandra, Astaroth)
3.Thugish_pond(Amy, Hilde)
4.Ceirnian(Hilde)
EVO2010

EVO2010冠军:梅原大吾
超级街霸4
1.梅原大吾(Ryu)
2.EG|Ricky Ortiz(Rufus、Chunli)
3.Infiltration(豪鬼)
4.Michael Rossington(E.Honda)
超级街霸2 高清重制版
1.Snake Eyez(Zangief)
2.DGV(Ryu)
3.梅原大吾(Ryu、拳王)
4.Quoc Hung Nguyen(拳王、Dee Jay)
铁拳6
1.Nin(Steve)
2.Rip(Law)
3.Mr.Naps(Bryan,Bruce)
4.Devil Jim(Julia)
月姬格斗 逝血之战再临
1.Garu(H-Kohaku, H-VSion)
2.Lord Knight(H-Kohaku)
3.Kusanagi(H-Aoko)
4.HF Blade(C-Ciel)
龙之子 VS 卡普空:终极全明星
1.EG|Marn(Zero, Alex, Tekkaman Blade)
2.KBeast(Yatterman-1, Batsu, Megaman Volnutt, Tekkaman, Yatterman-2)
3.EG|Justin Wong(Jun the Swan, Chun-Li, Ryu, Karas)
4.Kurasa(Doronjo, Chun-Li, Saki)
漫画英雄 VS 卡普空 2
1.EG|Justin Wong(Storm, Sentinel, Cyclops)
2.EMP|Sanford Kelly(Storm, Sentinel, Cable)
3.Clockw0rk(Strider Hiryu, Sentinel, Doctor Doom)
4.IFC Yipes(Storm, Magneto, Psylocke)
超级街霸4 女子组
1.aAa Kayane(Chunli)
2.DMG|BurnYourBra(Ken, Gouken, Rose)
3.Yellowgal(Chunli)
4.Lina Yu(Blanka)
EVO2011
超级街霸4 街机版
1.Fuudo(Fei Long)
2.BT|Latif(C.Viper)
3.TH|PoongKO(Seth)
4.MCZ|梅原大吾(Yun)
漫画英雄 VS 卡普空3
1.BOX Viscant(Wesker/Haggar/Phoenix, Wesker/Iron Man/Phoenix)
2.MCZ|DMG PR Balrog(Dante/Wolverine/Tron, Dante/Amaterasu/Wolverine)
3.EG|Justin Wong(She-Hulk/Wolverine/Akuma, Storm/Wesker/Akuma, Wolverine/Storm/Akuma)
4.coL.CC|ComboFiend(She-Hulk/Taskmaster/Spencer)
真人快打
1.EMP|Perfect Legend(Kung Lao)
2.vVv REO(Mileena, Cyrax)
3.JOP(Johnny Cage, Raiden)
4.NYChris G(Reptile)
苍翼默示录:连锁反应2
1.Spark(Hakumen)
2.Lord Knight(Litchi,Makoto)
3.MCZ|Tokido(Noel)
4.Zong One(Carl)
铁拳6
1.DMG|Kor(Bob)
2.Fab(Bob,Miguel)
3.Rip(Law)
4.JustFrameJames(Law,Baek)
EVO2012
超级街霸4 街机版 Ver.2012
1.WW.MCZ|Infiltration(豪鬼、Gouken)
2.AVM|GamerBee(Adon)
3.CVPR|PR Balrog(拳王)
4.eLive Qanba|小孩(Cammy)
超级街霸2X
1.MAO(铁面)
2.Kusumondo(E.Honda)
3.Quoc Hung Nguyen(Dee Jay、拳王)
4.MCZ|梅原大吾(拳王、Ryu)
终极漫画英雄 VS 卡普空 3
1.coL.CC Filipino Champ(Magneto/Dormammu/Doctor Doom, Magneto/Doctor Doom/Phoenix)
2.LxG Infrit(Nova/Spencer/Sentinel)
3.FC NYChris G(Morrigan/Doctor Doom/Akuma, Wesker/Ryu/Hawkeye, Morrigan/Doctor Doom/Hawkeye)
4.coL.CC Combofiend(Nova/Spencer/Hawkeye, She-Hulk/Taskmaster/Spencer)
街霸 X 铁拳 组队赛
1.WW.MCZ|Infiltration、WW.MCZ|Laugh(Rolento、Ryu)
2.CVapor|PR Balrog、EG|Ricky Ortiz(Ryu、Rufus)
3.MCZ|Tokido、RZR|Fuudo(Chunli、Ryu)
4.coL.CC|Combofiend、coL.CC|Mike Ross(Julia、Marduk)
真人快打
1.EMP|KN Perfect Legend(Kung Lao)
2.vVv NOS CD Jr.(Jax, Kabal, Rain)
3.Pig of the Hut(Kenshi, Mileena)
4.IGL|MIT(Johnny Cage, Reptile, Scorpion, Stryker)
拳皇13
1.CafeID MadKOF(Duo Lon, King, Kim, Chin)
2.IGL|Bala(Billy, Iori, Shen, Takuma, Ralf, Clark, Benimaru)
3.CafeID Verna(EX Iori, Duo Lon, Kim, Shen)
4.CafeID Guts(Saiki, EX Iori, Vice, Shen, Mr Karate)
刀魂5
1.Shining Decopon(Tira)
2.Shen Chan(Cervantes)
3.Something-Unique(Pyrrha)
4.Woahhzz(α Patroklos)
EVO2013
超级街霸4 街机版 Ver.2012
1.DM.MCZ|Xian(Gen)
2.MCZ|Tokido(豪鬼)
3.Infiltration(豪鬼、Ryu、Hakan)
4.EG|PR Balrog(拳王、Fei Long)
终极漫画英雄 VS 卡普空 3
1.FS.EMP|Flocker(Zero/Vergil/Hawkeye)
2.EG|Justin Wong(Wolverine/Storm/Akuma, Wolverine/Spencer/Frank West)
3.Angelic(Wolverine/Dormammu/Shuma-Gorath)
4.Cloud805(Zero/Vergil/Dante)
不义联盟
1.VxG.EMP|KDZ(Superman)
2.Crazy DJT 88(Green Lantern,Doomsday)
3.AGE|NYChrisG(Green Arrow, Black Adam)
4.EGP.FLK|MF Slayer909(Superman, Wonder Woman)
Super Smash Bros.Melee
1.MIOM|Mango(Fox, Falco)
2.Wobbles(Ice Climbers)
3.CT|Hungrybox(Jigglypuff)
4.Armada(Peach)
拳皇13
1.AS|Reynald(EX Kyo/Benimaru/Chin, EX Kyo/Benimaru/Kim, Kim/Benimaru/Chin, Benimaru/Takuma/Chin)
2.Woo(Ryo/Kim/Mai, Ryo/Takuma/Kim)
3.CafeId.RZR|MadKOF(King/Shen/Kim, Duo Lon/King/Kim, Duo Lon/Kim/Shen)
4.MCZ.Tokido(EX Iori/Mr. Karate/Kim)
街霸 X 铁拳 Ver.2013
1.Infiltration(Jin/Alisa)
2.EG|Justin Wong(Hwoarang/Chun-Li)
3.MOV(Law/Cammy, Law/Nina)
4.LU|Alex Valle(Yoshimitsu/Lars)
铁拳TT2
1.CafeId|Knee(Devil Jin/Bruce, Dragunov/Marduk, Heihachi/Lars)
2.Eightarc|Bronson(Ogre/Jinpachi)
3.AGE|StringBean(Bob/Alisa)
4.CafeId|NIN(Devil Jin/Lars, Steve/Marduk)
真人快打
1.Crazy DJT 88(Cyrax)
2.VxG.EMP|REO(Kabal)
3.My God 88(Sonya, Liu Kang)
4.Forever King 88(Kung Lao, Kenshi)
P4U
1.Yume(Aigis)
2.Lord Knight(Mitsuru Kirijo)
3.BananaKen(Shadow Labrys)
4.Brkrdave(Teddie)
2022年
格斗游戏大赛EVO 2020公布比赛项目参赛选手人数排行
格斗游戏大赛EVO 2020公布了参赛选手人数排行。《任天堂明星大乱斗SP》依然拥有强大的群众基础支持,而新作《碧蓝幻想VERSUS》热度也不错,甚至超过了《铁拳7》。以下为详细排名:
1:《任天堂明星大乱斗SP》
2:《街头霸王5 冠军版》
3:《碧蓝幻想VERSUS》
4:《铁拳7》
5:《龙珠斗士Z》
6:《夜下降生Exe:Late[cl-r]》
7:《剑魂6》
8:《侍魂 晓》

赛事将于7月31日至8月2日在拉斯维加斯举办。
2023年
预定在 2023 年 8 月 4 日至 6 日于拉斯维加斯所举办的世界最大格斗游戏电竞比赛「EVO 2023」,在公开了 8 款主要比赛的参赛作品。

本次的比赛项目包含《铁拳7》《真人快打11终极版》等经典作品以外,预计在今年 6 月上市的《街头霸王6》也在其中,此外还有《月姬格斗Type Lumina》和久违数年回归的《漫威VS卡普空3》,除了公开参赛作品阵容以外,即日起也在官方网站开放参加者报名,感兴趣的格斗好手们不妨到官网上确认吧。
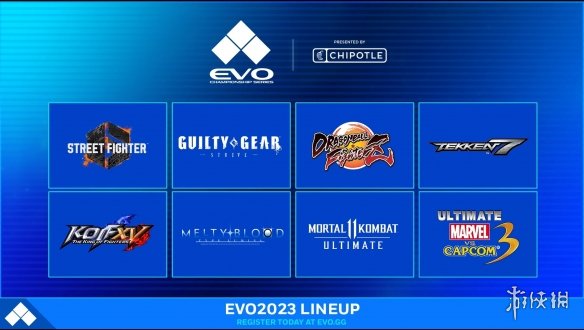
《街头霸王6(Street Fighter 6)》
《罪恶装备 奋战(Guilty Gear -Strive-)》
《真人快打11 终极版(Mortal Kombat 11 Ultimate)》
《铁拳7(Tekken 7)》
《拳皇15(The King of Fighters XV)》
《月姬格斗 TYPE LUMINA(Melty Blood:Type Lumina)》
《龙珠斗士Z(Dragon Ball FighterZ)》
《漫威VS卡普空3(Ultimate Marvel vs. Capcom 3)》


2024年
格斗游戏大赛 EVO 2024 确定明年 4 月 27 日-29 日举行
IT 之家 8 月 7 日消息,在格斗游戏大赛 EVO 2023 期间,EVO 总经理 Rick Thiher 透露了 EVO Japan 2024 和 EVO 2024 的日期。EVO 明年将恢复到 7 月的赛程,并且已经准备了一项新赛事。
据了解,EVO 2023 的出席人数创下新纪录,超过 2 万人,创始人汤姆・坎农(Tom Cannon)和托尼・坎农(Tony Cannon)获得了拉斯维加斯的钥匙,内华达州现在正式确定 8 月 6 日为 EVO Day。

IT 之家从 Thiher 获悉,EVO Japan 将于 2024 年 4 月 27 日 -29 日在东京回归,在 2020 年东京奥运会举办地 Ariake GYM-EX 举行,由乐敦赞助,标志着该赛事恢复到 7 月的日程。

在 EVO Japan 2024 揭晓后,Thiher 确认 EVO 将重返拉斯维加斯的曼德勒湾度假村及赌场。
.
.
.
.
.
.