巩义网站优化网站开发用mvc多吗
Lombok
1.作用:简化javabean开发
2.使用:a.下插件 -> 如果是idea2022不用下载了,自带b.导lombok的jar包c.修改设置
1.lombok介绍
Lombok通过增加一些“处理程序”,可以让javabean变得简洁、快速。
Lombok能以注解形式来简化java代码,提高开发效率。开发中经常需要写的javabean,都需要花时间去添加相应的getter/setter,也许还要去写构造器、equals等方法,而且需要维护。
Lombok能通过注解的方式,在编译时自动为属性生成构造器、getter/setter、equals、hashcode、toString方法。出现的神奇就是在源码中没有getter和setter方法,但是在编译生成的字节码文件中有getter和setter方法。这样就省去了手动重建这些代码的麻烦,使代码看起来更简洁些。
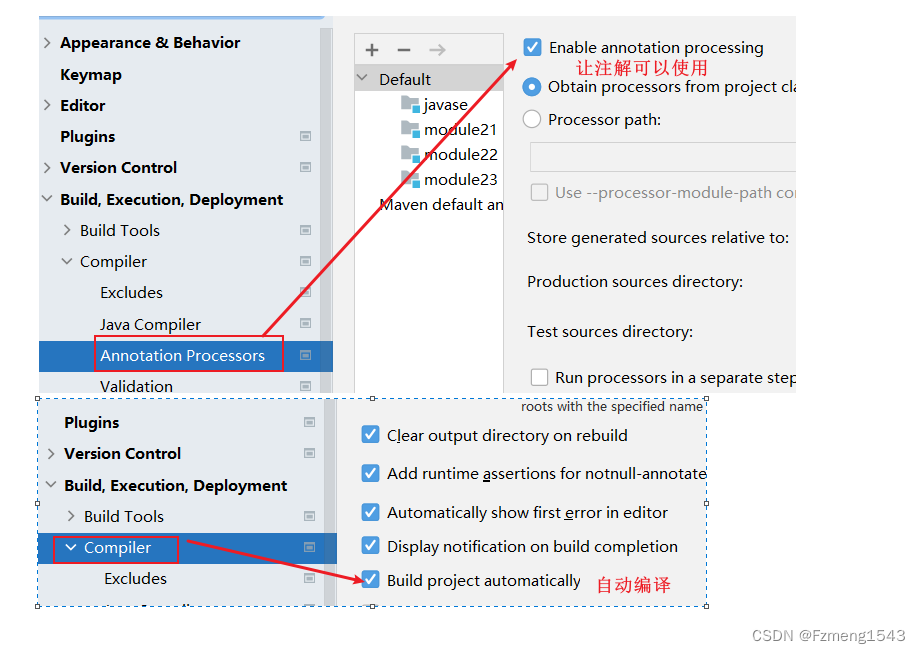
2.lombok常用注解
@Getter和@Setter
- 作用:生成成员变量的get和set方法。
- 写在成员变量上,指对当前成员变量有效。
- 写在类上,对所有成员变量有效。
- 注意:静态成员变量无效。
@ToString
- 作用:生成toString()方法。
- 注解只能写在类上。
@NoArgsConstructor和@AllArgsConstructor
- @NoArgsConstructor:无参数构造方法。
- @AllArgsConstructor:满参数构造方法。
- 注解只能写在类上。
@EqualsAndHashCode
- 作用:生成hashCode()和equals()方法。
- 注解只能写在类上。
@Data
- 作用:生成get/set,toString,hashCode,equals,无参构造方法
- 注解只能写在类上。
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Person {private String name;private Integer age;
}public class Test01 {public static void main(String[] args) {Person person = new Person();person.setName("涛哥");person.setAge(10);System.out.println(person.getName()+"..."+person.getAge());System.out.println("================");Person p1 = new Person("三上", 28);System.out.println(p1.getName()+"..."+p1.getAge());}
}